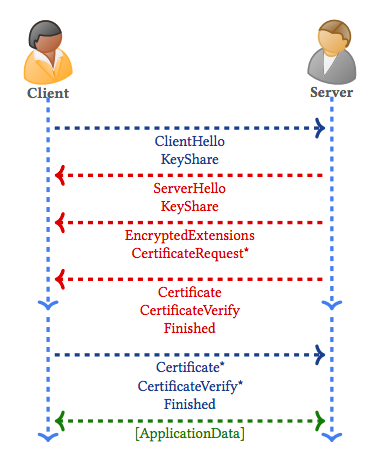
The new TLS 1.3 protocol as seen in RFC 8446 can be described very well by looking at the new handshake:
Client: Key Exchange — Establish shared keying material and select the
cryptographic parameters. Everything after this phase is
encrypted. ( Spooky! )
Server: Server Parameters: Establish other handshake parameters
(whether the client is authenticated, application-layer protocol
support, etc.).
Client: Authentication – Authenticate the server (and, optionally, the
client) and provide key confirmation and handshake integrity.
And thats it…
I would say that its quite an improvement over TLS 1.2. Lets take this apart and look at the differences between the constituent elements of the client hello.
TLS 1.2 Client Hello:
The first HTTP packet to touch the server from the client is called the hello message. It consists of everything you may need to start an encrypted conversation:
A preferred protocol version designation
A GMT time variable
A 28 byte randomly generated structure
A session ID
A list of supported cipher suites
A list of supported compression methods
Possible Extensions information
Getting to this level of detail is only possible by going to the RFC pages ( Request for Comment — its like the internet Rosetta Stone ) and reviewing the C code and its component expansions that the IETF explains pretty well. Its important to learn the C programming language — one reason in particular is that sometimes all the documentation you will have on something will be an implementation written in C. And the C language is so universal, it actually has an ANSI standard, the same way we have a standard for how long a meter is or how much a kilogram weighs — pretty cool huh? You can read more about it on the ANSI website or wikipedia.
So, speaking of implementations — this is now getting to the bigger picture for this read. Its critical to remember that as we learn about TLS and the comparison of 1.2 to 1.3, we are talking about standards. Lets take a look at the TLS 1.3 client hello:
TLS 1.3 Client Hello:
A preferred protocol version designation for TLS 1.2 Backward Compatibility
A 32 byte randomly generated structure
A legacy session ID – another BC component for TLS 1.2
A list of supported cipher suites with PSK establishment
Legacy compression methods – BC for TLS 1.2, otherwise one byte set to zero
Extension information
The modification to the TLS protocol shows up right away in the hello message as it will have already gone through the trouble of establishing a pre-shared key for the protocol it thinks the server is likely to support. This is the basis for the improvement model revealing itself in the first hello message leading to a more performant interaction. Remember, there are only two more steps until a symmetrically encrypted link is established and communication begins.
Below is an excerpt from a paper published by the University of Oxford on the scientific analysis of the TLS 1.3 standard using the Tamarin Prover by Cas Cremers, et al:
The default mode of TLS 1.3 allows for ephemeral Diffie–Hellman (DH) keys to be established either over a finite field or using elliptic curves. In an initial (EC)DHE handshake, as depicted in Figure 1, the client sends a ClientHello message containing a random nonce, i.e. a freshly generated random value, and a list of symmetric algorithms. The client also sends a set of DH key shares and the associated groups, KeyShare, and potentially some other extensions.
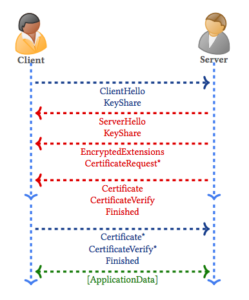 This is figure 1, taken straight from the paper in question.
This is figure 1, taken straight from the paper in question.
The magic of this improvement lies in the assumption of a usable Key Exchange method that you can see when the client sends a ECDHE KeyShare in the first request along with its very small list of supported ciphers. This results in a 3 step handshake instead of twenty thousand or however many there were before. Massive improvement.
If you want to check out what I mean by spooky, I recommend watching a very succinct and clean review of Elliptic Curve Crypto with a good explanation of the math behind the Diffie-Hellman key exchange by Will Raedy: Link
On a final note before we move on…The important thing that I want to remember here is that regardless of this new standard, and regardless of someone saying:
“I’m using TLS 1.3“,
you need to look a little deeper than that pretty little fractionated numeric value. When you look at little closer, you will find that TLS is a design standard, much like ISO27001 is a standard. Standards have versions, and they also have variability around the way they are implemented.
Go here: https://tls.ctf.network and watch what happens!
At the time of this writing, there is a script on the page that tests which version you are using. Visiting it with Chrome Version 68.0.3440.106 (Official Build) (64-bit), I got the following message:
You are connecting with TLSv1.3 Draft 23.
And….. whoah… Yesterday Firefox was connecting to said page and the message came back with Draft 28. Now the page wont even render… strange: FireFox Quantum version 61.0.2 seems to have a problem as Im getting a single line text in the response from the ctf domain that says:
You are connecting with TLSv1.2, you can enable TLS 1.3 using the latest Chrome Canary (chrome://flags/#ssl-version-max) or Firefox Nightly.
Firefox seems to be having strange difficulties of late….
Anyway… Lets turn our attention over to the GitHub repo that manages all the mainstream TLS implementation projects here.
There are about 20 implementations there, each that specify the draft of TLS 1.3 from the IETF that they are using for their frame of reference. One in particular you may have heard of is BoringSSL, which was spawned by a fork from Google back in mid 2014 when they decided to sunset their use of OpenSSL. You can see they wrote it in C, they work with two drafts and they directly reference RFC 8446 ( don’t you just love those :).
Key takeaways:
- TLS 1.3 is ready for action ( symmetrically encrypted communication ) within 1.5 round trips between the client and server. 1.2 was boasting 6 steps of communication.
- TLS 1.3 accomplishes this feat by making a key sharing protocol assumption and packages a PSK using the Diffie Helman protocol and available cipher suites.
- The Cipher Suite options make this really exciting because instead of 317 there are five.
Some things we will look into in our part 2 article:
P-256
X25519
HelloRetryRequest
resumption
0-RTT
KeyUpdate
Spooky! 🙂